
Carles Bellver
<bellverc@si.uji.es>
Jordi Adell
<jordi@edu.uji.es>
Universitat Jaume I
Publicado en Net Conexión 1, 1995. págs. 88-92
Desde el año 94 estamos viviendo un auténtico boom de la Internet que ha metido la red en todos los hogares a través de los medios de comunicación. Para muchos de los usuarios llegados en esta última hornada la Internet es el World-Wide Web. La realidad, sin embargo, no es ésta, o al menos no ha sido siempre así. De hecho, las pantallas multimedia y los enlaces entre hipertextos propios del WWW son ingredientes relativamente recientes de la red.
Los orígenes del proyecto World-Wide Web se remontan al año 1989 en el CERN (el laboratorio europeo de física de partículas, en Ginebra). Tim Berners-Lee se enfrentó al problema de grupos de investigadores geográficamente dispersos que deseaban acceder a recursos disponibles en puntos distantes del sistema informático del CERN: bases de datos, resultados experimentales, informes de resultados, listas de direcciones, etc. Su idea fue aprovechar las posibilidades que ofrecían las redes de ordenadores. La interconexión de recursos permitía acceder a ellos desde cualquier punto de las instalaciones, y era concebible que se estableciesen enlaces (links) entre los recursos para saltar rápidamente de unos a otros. Por ejemplo: saltar desde la ficha de un investigador en la base de datos de personal hasta los informes de sus experimentos, y después hacia los datos de sus colaboradores. Para conseguir este propósito se diseñó una arquitectura teórica compleja, que ponía en juego tres estándares ahora bien conocidos: el protocolo HTTP, el lenguaje HTML y los URL. Las primeras realizaciones prácticas se ensayaron en 1991, y pronto se vio que el sistema resultaba también idóneo a otra escala: toda la Internet se podía llegar a ver como una red o una telaraña de recursos a través del World-Wide Web. El NCSA (El National Center for Supercomputing Applications, en Illinois) y el MIT (El Instituto de Tecnología de Massachusetts) decidieron sumarse al proyecto. Sin embargo, aún faltaba algo fundamental: un interface sencillo que explotara las posibilidades del sistema y acercara de verdad la Internet a las ventanas de los usuarios. Por el momento el único modo de acceder al WWW era por medio de terminales de texto que mostraban la información línea tras línea y enumeraban los enlaces al final. El usuario, para seguir uno de estos enlaces, debía teclear su número correspondiente. Una mecánica un tanto rudimentaria que difícilmente ganaba adeptos.
La infraestructura de red en aquella época era, vista con ojos actuales, francamente pobre. El backbone estatal de RedIRIS tenía 64 Kbaudios. en sus mejores enlaces, y lo normal era conectar una institución a 9.600 baudios. Menos que lo que ahora tenemos en casa en nuestro modem personal. Pero la Internet no era todavía un mundo de imágenes y colores. Era texto y ficheros informáticos. Los usuarios eran, principalmente, los gurús informáticos de los servicios informáticos de las universidades y centros de investigación. A nadie se le ocurría poner arrobas en su tarjeta, y la gente que tenía correo electrónico solía contestar a todos los mensajes.
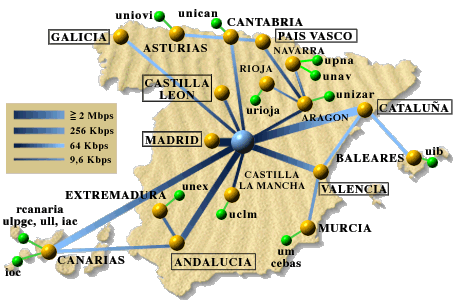
Mapa de interconexión de RedIRIS © RedIRIS 1995
En este ambiente de excitación por el descubrimiento de un nuevo mundo, algunos grupos dentro de las Universidades se planteaban ser no sólo consumidores de información, sino también productores y distribuidores. Tras diversas pruebas, en el verano de 1992 la Universitat Jaume I instaló y registró en la Universidad de Minnesota el primer servidor Gopher del Estado Español. Enseguida comenzaron a aparecer nuevos servidores. Al igual que en nuestro caso su objeto era funcionar como CWIS (Campus Wide Information Systems), sistemas de información del Campus, aunque se pudieran consultar desde cualquier parte del mundo. El gopher era sencillo: servía a través de la red textos codificados como ASCII o ISO Latin-1, imágenes, sonidos y cualquier tipo de fichero; no hacia falta transformar la información, bastaba con guardarla como “sólo texto”. Los menús jerárquicos reproducían la estructura de directorios creada en el servidor. Y, encima, todo era gratis. El gopher fue la estrella de la Internet durante el 92 y buena parte del 93.
Frente al Gopher, que no requería tratar la información, el WWW complica la vida de los proveedores de información al tiempo que facilita la de los usuarios. El interface hipertextual posee una enorme potencia para estructurar corpus amplios y complejos de información frente al sencillo sistema de árboles de menús del Gopher. El lenguaje en el que deben escribirse los textos en el Web (para definir formatos o enlaces, introducir imágenes, etc.), el HyperText Markup Language (HTML), ofrece numerosas posibilidades, pero también encarece la elaboración de la información. Frente al mero texto del Gopher (y las imágenes o sonidos como ficheros independientes), el Web contrapone mayor riqueza y más trabajo. Diseñar y escribir hipertextos en HTML es laborioso. Aún contando con la ayuda de numerosas herramientas de software, resulta imprescindible conocer la sintaxis del lenguaje para no desperdiciar todo su potencial. En ningún caso basta con un “Save as...”
La primera versión de Mosaic funcionaba sólo bajo entorno Unix Window, pero estaban anunciadas las versiones para Macintosh y Windows. Fue entonces cuando, desde el Departamento de Educación de la Universitat Jaume I, nos decidimos a experimentar con el WWW. Sabíamos de ensayos en este sentido en otras universidades españolas, pero tras unos meses de funcionamiento en pruebas registramos en el CERN nuestro servidor y, nuevamente, fue el primero del Estado.
Una atalaya privilegiada para contemplar la evolución de la Internet en España ha sido el mapa de servicios. El mapa sensible (ISMAP) de la Internet en España es, sin duda, el recurso más conocido de los que ofrece el servidor WWW de la Universitat Jaume I y el que más tráfico genera (<URL:http://www.uji.es/spain_www.html>). Por ejemplo, la semana del 18 al 24 de septiembre el mapa de España fue consultado 7.605 veces, el de Madrid 2.306 y el de Cataluña 2.095. Esa misma semana nuestro servidor registró 133.201 transacciones, de las cuales sólo un 28% correspondieron a nodos españoles.
Los mapas (o el mapa, porque al principio sólo era uno) comenzaron como una forma de sacar partido a una de las características más espectaculares del WWW: la posibilidad de convertir en un enlace hipertextual no sólo una palabra o frase, sino también una zona de un gráfico. Un ISMAP no es más que una imagen gráfica con zonas vinculadas a distintos URL. Cuando el usuario “pincha” con el ratón sobre la imagen su cliente comunica las coordenadas del clic al servidor, y este se encarga de resolver a qué URL corresponden y efectuar la conexión.
El diseño de los mapas ha tenido que evolucionar a lo largo del tiempo como resultado de la progresión de la Internet en España. En cada cambio se ha intentado incluir la máxima cantidad de información en el mínimo espacio. La razón es evidente: cuando menor sea el tamaño de la imagen, menos ocupa en KBytes y menos se tarda en recuperar el fichero por la red. También se optó por separar el mapa inicial, en el que en 1993 cabían perfectamente todos los recursos, en un mapa por comunidad autónoma. Tras el éxito de Mosaic, su sucesor Netscape, y la explosión del World-Wide Web, hoy los mapas incluyen aproximadamente 500 recursos y el ritmo de crecimiento es de más de 25 por semana. Pero el cambio es más que cuantitativo: una proporción creciente de las novedades procede de fuera del círculo universitario. Empresas del sector informático, proveedores de conectividad, asociaciones culturales, la prensa diaria... Quizá las expectativas que en ocasiones se han querido difundir entre el gran público (la Internet para todos y todo en la Internet) no eran tan desorbitadas. Quizá.
HTTP HTML URL |
|
La facilidad de uso del World-Wide Web descansa sobre la base de una compleja arquitectura de estándares.
HTTP HyperText Transfer Protocol. Un protocolo de comunicaciones para transferir los documentos de un punto a otro de la red. La integración del estándar MIME (Multipurpose Internet Mail Extensions) permite enviar todo tipo de ficheros que incluyan texto, imágenes, voz, etc. HTML El HyperText Markup Language. Un lenguaje para estructurar el contenido de los documentos por medio de marcas que se insertan en el texto. Estas marcas posibilitan la definición de encabezamientos, formatos, figuras o enlaces con otros documentos. El HTML cumple las normas del estándar ISO SGML (Standard Generalized Markup Language). URL Los Uniform Resource Locators. Una notación para hacer referencia a cualquier recurso presente en la red. Los enlaces apuntan a otros documentos por medio de sus URL. |
Los protocolos de la red |
|
Desde antes del HTTP se han venido utilizando diversos protocolos en la Internet. El World-Wide Web está sirviendo para integrarlos. Telnet Protocolo que permite la utilización remota de una aplicación desde otro ordenador conectado a la red. SMTP El Simple Mail Transfer Protocol. Es el protocolo utilizado por el correo electrónico. Se pensó para transmitir texto ASCII, pero las extensiones MIME (Multipurpose Internet Mail Extensions) han hecho posible intercambiar cualquier tipo de información: HTML, imágenes, etc. FTP El File Transfer Protocol. Protocolo de transferencia de ficheros. NNTP Network News Transfer Protocol. Protocolo de comunicación del sistema de noticias de la red (Usenet News). Gopher Utilizado por los servidores gopher. WAIS Wide Area Information Systems. Protocolo para la consulta de bases de datos de textos. |
RedIRIS |
|
RedIRIS fue creada en el año 1988 por el Plan Nacional de Investigación y Desarrollo con el objetivo de impulsar la interconexión de recursos informáticos entre Universidades y centros de investigación públicos. Cuenta en la actualidad con más de 170 organizaciones afiliadas. Hasta 1993 fue gestionada por Fundesco (la Fundación para el Desarrollo de la Función Social de las Comunicaciones). Desde enero de 1994 está gestionada por el Consejo Superior de Investigaciones Científicas (CSIC).
RedIRIS ofrece a sus afiliados conexión a la Internet y numerosos servicios como mensajería electrónica, directorio, News, información (servidores FTP, Archie, Gopher y WWW) y experimenta con los del futuro (ATM y MBONE), ayuda a los usuarios en el uso de la red (infoiris), etc. Además, RedIRIS es registro delegado de Internet en España y NOC (Network Operation Center) de la red académica española. Servicios de información:
|
Edición de HTML |
Un documento HTML contiene texto ASCII o ISO Latin-1 con marcas inscritas que siguen una sintaxis estándar. Por ello, cualquier editor o procesador de texto sirven para escribir HTML. Sin embargo, teclear las marcas resulta laborioso y es proclive a errores. Resulta pues más razonable utilizar alguna herramienta de software que automatice el proceso. Cuándo se instalaban los primeros servidores WWW en España apenas existían herramientas de este tipo. Carles Bellver desarrolló en la Universitat Jaume I unas extensiones para el editor de texto BBEdit (el más popular en entornos Macintosh) que facilitaban la creación de HTML: <http://www.uji.es/bbedit-html-extensions.html> El uso de editores con extensiones HTML es una de las tendencias en cuanto a producción de documentos para el WWW. Otras son la conversión automática desde otros formatos y las herramientas gráficas seudo WYSIWYG. |
Gráfico de la evolución del tráfico mundial por protocolo
|
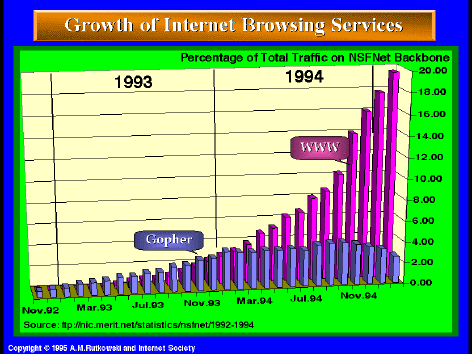
|
![]() Esta es una auténtica página del servidor WWW del grupo de NTI de la UJI.
Copyright 1996 NTI-UJI.
Esta es una auténtica página del servidor WWW del grupo de NTI de la UJI.
Copyright 1996 NTI-UJI.